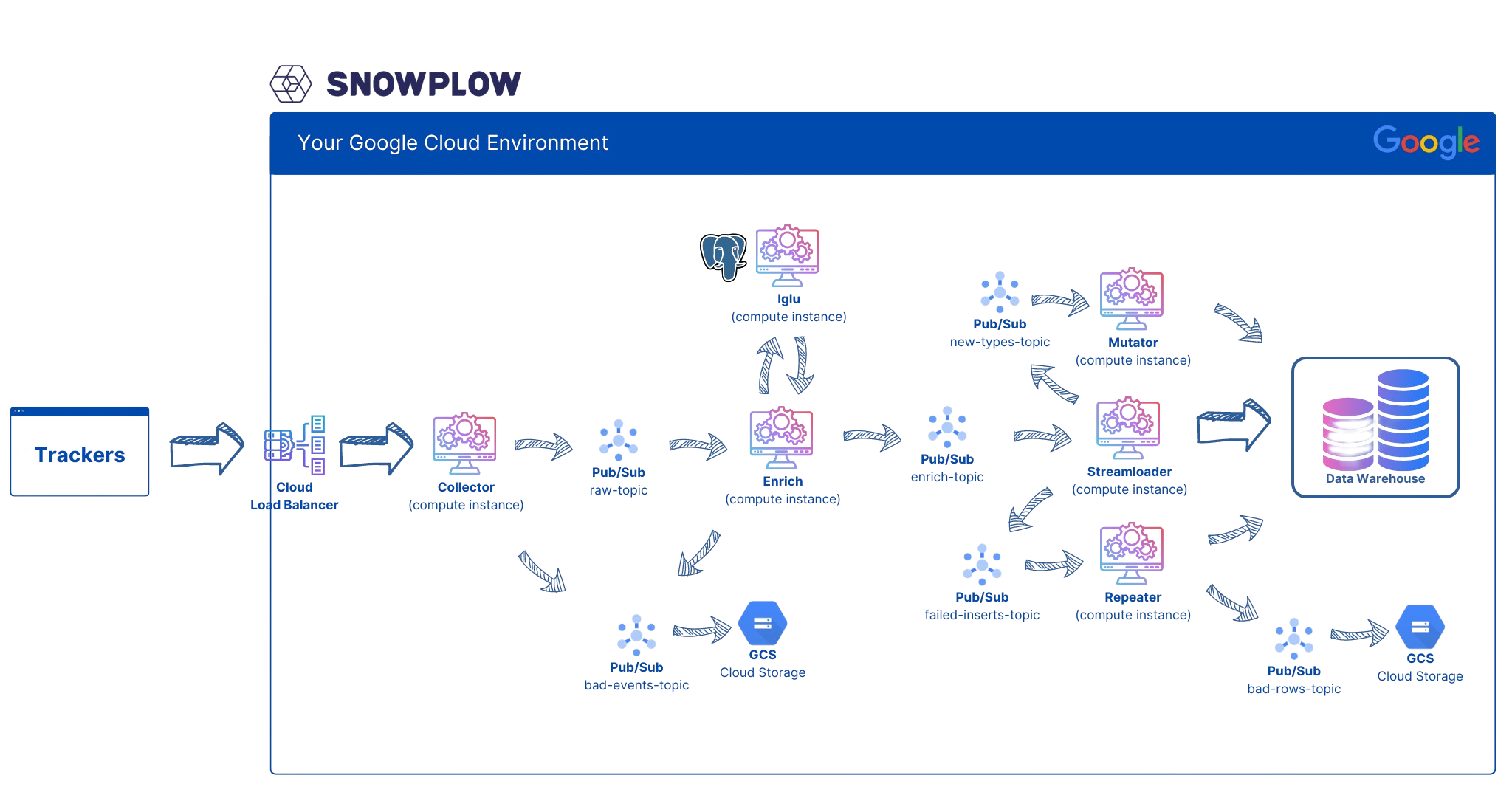
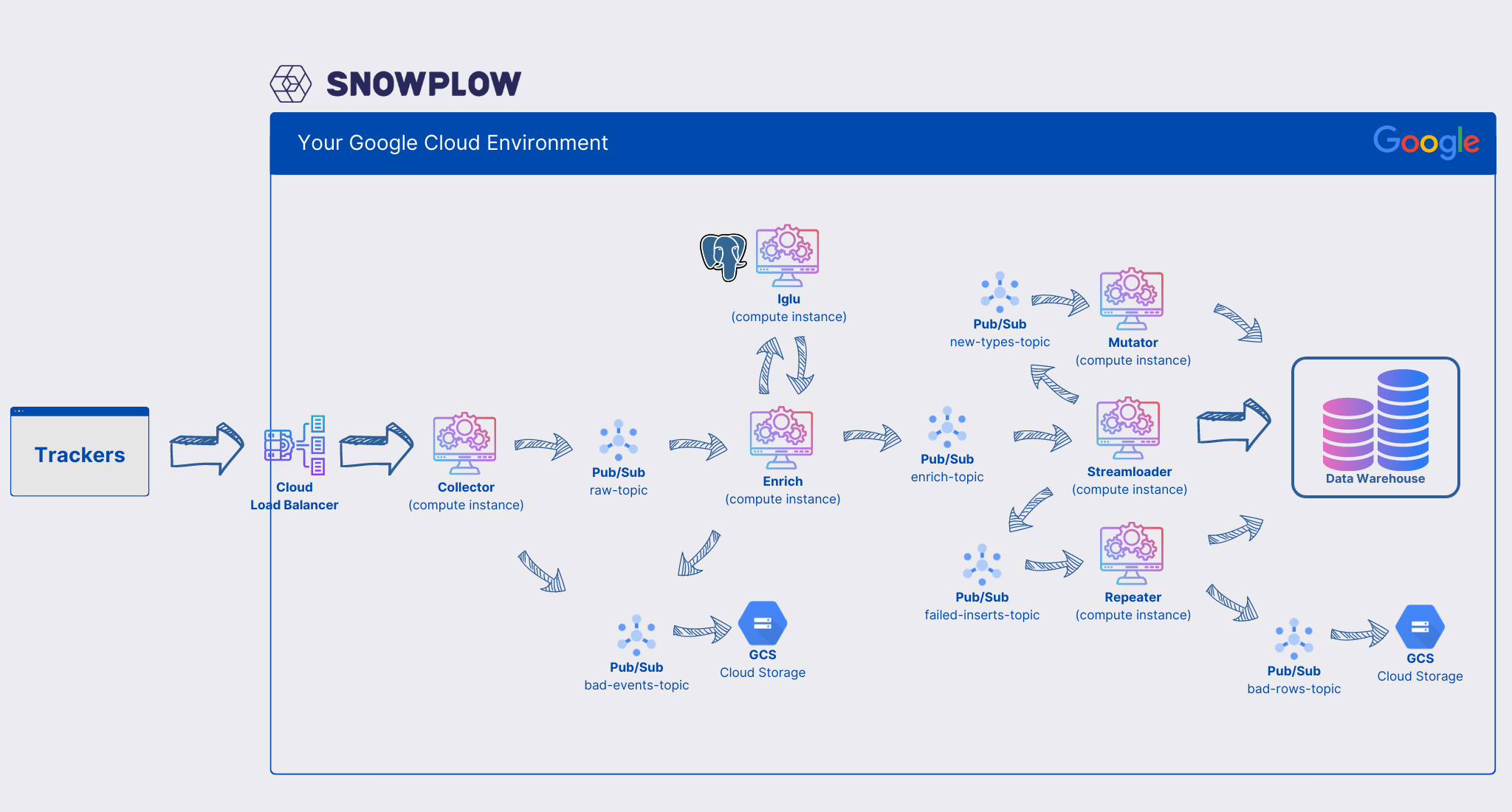
Deploying Snowplow 3 - Kubernetes Cluster
30 Sep 2024This is the Part 3 of our post that explains how to deploy Snowplow on GCP and GKE. In part 1 we gave a high level overview of the architure of our deployment. In part 2 we went into full details of how to create the infrastrucure required for this deployment using Terraform. In this part, we explain in details, how to deploy the services on Kubernetes. Note that the implemtation mentioned here does not include horizontal scaling HPA, and must be manually updated to handle increased traffic.
We will go over HPA in a future post. In this post, we go over these resources:
- Namespace
- Service Account
- Iglu Service
- Collector
- Enrich
- Data Warehouse Loaders
- Streamloader
- Repeater
- Mutator
- Mutator Init
- Endpoint
- Wrap Up
Namespace
In our implementation, we deploy everything in snowplow namespace. We need to create the namespace first:
# snowplow/namespace.yaml
apiVersion: v1
kind: Namespace
metadata:
name: snowplow
Service Account
As we mentioned in part 2, in order to authenticate our GKE deployments, we use GKE’s Workload Identity Federation. The way this works is that we create a GKE service account named snowplow-service-account in snowplow namespace and let our deployments to use this service account by mentioning:
serviceAccountName: snowplow-service-account
in deployment’s template spec. In part 2, we allowed this service account to bind to GCP service account snowplow that we created specially for this purpose and gave it all the required permissions. So let’s create the GKE service account:
# snowplow/service-account.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
annotations:
iam.gke.io/gcp-service-account: snowplow@<GCP-PROJECT>.iam.gserviceaccount.com
name: snowplow-service-account
namespace: snowplow
Note that snowplow@<GCP-PROJECT>.iam.gserviceaccount.com is the name of GCP service account we created in part 2. You should change <GCP-PROJECT> to the name of your GCP project.
Iglu Service
Perfect. Next, let’s deploy Iglu service. Iglu Server in Snowplow’s documentation words:
The Iglu Server is an Iglu schema registry which allows you to publish, test and serve schemas via an easy-to-use RESTful interface.
We divide Iglu service declaration (and all other service to come next) into a config file and a deployment file. Here is the config file for the Iglu service. Here you can find full documentation for Iglu Server Configuration. Note that this is the documentation for the latest version, but it gives a very good overview of the options for older version.
Also note that we make sure we use an older image that does not require us to accept the new Snowplow Limited Use License. Therefore if you don’t want to be limited by the new license, make sure you use an older version and make sure you don’t have:
license {
accept = true
}
in your config. This applies to all the configurations we show next as well.
# snowplow/iglu-config.yaml
kind: ConfigMap
apiVersion: v1
metadata:
name: iglu-configmap
namespace: snowplow
data:
iglu-server.hocon: |
{
"repoServer": {
"interface": "0.0.0.0"
"port": 8080
"threadPool": "cached"
"maxConnections": 2048
}
"database": {
"type": "postgres"
"host": "<igludb_ip_address>"
"port": 5432
"dbname": "<igludb_db_name>"
"username": "<igludb_username>"
"password": "<igludb_password>"
"driver": "org.postgresql.Driver"
pool: {
"type": "hikari"
"maximumPoolSize": 5
connectionPool: {
"type": "fixed"
"size": 4
}
"transactionPool": "cached"
}
}
"debug": false
"patchesAllowed": true
"superApiKey": "<UUID>"
}
Note that you need to make sure you full the following values to match with the ones we used in part 2 to create the resources:
- igludb_ip_address
- igludb_db_name
- igludb_username
- igludb_password
Also, you need to generate a UUID for superApiKey. Make sure to keep it private. After you created and applied the config file, let’s create and apply the deployment:
# snowplow/iglu.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: iglu-server
namespace: snowplow
spec:
selector:
matchLabels:
app: iglu
replicas: 2
revisionHistoryLimit: 1
template:
metadata:
labels:
app: iglu
spec:
securityContext:
runAsUser: 1000
runAsGroup: 3000
fsGroup: 2000
containers:
- name: iglu-server
image: snowplow/iglu-server:0.11.0
command:
[
"/home/snowplow/bin/iglu-server",
"--config",
"/snowplow/config/iglu-server.hocon",
]
imagePullPolicy: "IfNotPresent"
env:
- name: JAVA_OPTS
value: -Dorg.slf4j.simpleLogger.defaultLogLevel=info
volumeMounts:
- name: iglu-config-volume
mountPath: /snowplow/config
resources:
requests:
memory: "256Mi"
cpu: "100m"
limits:
memory: "1.5Gi"
volumes:
- name: iglu-config-volume
configMap:
name: iglu-configmap
items:
- key: iglu-server.hocon
path: iglu-server.hocon
---
apiVersion: v1
kind: Service
metadata:
name: iglu-server-service
namespace: snowplow
spec:
selector:
app: iglu
ports:
- name: http
protocol: TCP
port: 80
targetPort: 8080
Collector
Collector is the service that event traffic sees first, so let’s implement it. Again we divide collector declaration into two parts, config and deployment. Let’s start with configuration. In the configuration file below, make sure you replace <GCP-PROJECT> with the name of your project. Also the collector service has three endpoints that can be customized:
- tracker endpoint:
/com.snowplowanalytics.snowplow/tp2 - redirect endpoint:
/r/tp2 - iglu endpoint:
/com.snowplowanalytics.iglu/v1
in the config file below we have customized these endpoints to /v1/track, /v1/redirect, and /v1/iglu just to show how it’s done. You can see the full configuration document for the latest version here. Again make sure you use an older version if you don’t want to be limited by the new license.
# snowplow/collector-config.yaml
kind: ConfigMap
apiVersion: v1
metadata:
name: collector-configmap
namespace: snowplow
data:
config.hocon: |
collector {
interface = "0.0.0.0"
port = 8080
ssl {
enable = false
redirect = false
port = 8443
}
paths {
"/v1/track" = "/com.snowplowanalytics.snowplow/tp2"
"/v1/redirect" = "/r/tp2"
"/v1/iglu" = "/com.snowplowanalytics.iglu/v1"
}
p3p {
policyRef = "/w3c/p3p.xml"
CP = "NOI DSP COR NID PSA OUR IND COM NAV STA"
}
crossDomain {
enabled = false
domains = [ "*" ]
secure = true
}
cookie {
enabled = true
expiration = "365 days"
name = sp
domains = []
fallbackDomain = ""
secure = true
httpOnly = false
sameSite = "None"
}
doNotTrackCookie {
enabled = false
name = ""
value = ""
}
cookieBounce {
enabled = false
name = "n3pc"
fallbackNetworkUserId = "00000000-0000-4000-A000-000000000000"
forwardedProtocolHeader = "X-Forwarded-Proto"
}
enableDefaultRedirect = false
redirectMacro {
enabled = false
placeholder = "[TOKEN]"
}
rootResponse {
enabled = false
statusCode = 302
headers = {}
body = "302, redirecting"
}
cors {
accessControlMaxAge = "5 seconds"
}
prometheusMetrics {
enabled = false
}
streams {
good = snowplow-raw
bad = snowplow-bad-1
useIpAddressAsPartitionKey = false
sink {
enabled = google-pub-sub
googleProjectId = "<GCP-PROJECT>"
backoffPolicy {
minBackoff = 1000
maxBackoff = 1000
totalBackoff = 10000
multiplier = 1
}
}
buffer {
byteLimit = 1000000
recordLimit = 500
timeLimit = 500
}
}
telemetry {
disable = true
url = "telemetry-g.snowplowanalytics.com"
userProvidedId = ""
moduleName = "collector-pubsub-ce"
moduleVersion = "0.2.2"
autoGeneratedId = ""
}
}
akka {
loglevel = WARNING
loggers = ["akka.event.slf4j.Slf4jLogger"]
http.server {
remote-address-header = on
raw-request-uri-header = on
parsing {
max-uri-length = 32768
uri-parsing-mode = relaxed
}
max-connections = 2048
}
}
And now the collector implementation itself:
# snowplow/collector.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: collector-server
namespace: snowplow
spec:
selector:
matchLabels:
app: collector
replicas: 2
revisionHistoryLimit: 1
template:
metadata:
labels:
app: collector
spec:
# Prevent the scheduler from placing two pods on the same node
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 10
podAffinityTerm:
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- collector
topologyKey: "kubernetes.io/hostname"
serviceAccountName: snowplow-service-account
containers:
- name: collector-server
image: snowplow/scala-stream-collector-pubsub:2.10.0
command:
- "/home/snowplow/bin/snowplow-stream-collector"
- "--config"
- "/snowplow/config/config.hocon"
imagePullPolicy: "IfNotPresent"
env:
- name: JAVA_OPTS
value: -Dorg.slf4j.simpleLogger.defaultLogLevel=info
volumeMounts:
- name: collector-config-volume
mountPath: /snowplow/config
resources:
requests:
memory: "128Mi"
cpu: "250m"
limits:
memory: "1Gi"
volumes:
- name: collector-config-volume
configMap:
name: collector-configmap
items:
- key: config.hocon
path: config.hocon
---
apiVersion: cloud.google.com/v1
kind: BackendConfig
metadata:
name: collector-backendconfig
namespace: snowplow
spec:
timeoutSec: 60
healthCheck:
checkIntervalSec: 10
timeoutSec: 10
healthyThreshold: 3
unhealthyThreshold: 5
type: HTTP
requestPath: /health
port: 8080
logging:
enable: false
---
apiVersion: v1
kind: Service
metadata:
name: collector-server-service
namespace: snowplow
annotations:
cloud.google.com/backend-config: '{"default": "collector-backendconfig"}' # this is only required if you run on GKE
spec:
selector:
app: collector
type: ClusterIP
ports:
- protocol: TCP
port: 8080
targetPort: 8080
Enrich
Going from right to left in the architecture diagram in part 1, next is Enrich server. We are doing basically the same thing as we did for the collector and divide it into a configuration file and a deployment file. Here is the latest documentation for the configuration of the enrich server
Note that in the configuration below you need to replace:
<SALT>with some arbitrary random string<Iglu superApiKey>with the samesuperApiKeyUUID you used in Iglu server configuration above
# snowplow/enrich-config.yaml
kind: ConfigMap
apiVersion: v1
metadata:
name: enrich-configmap
namespace: snowplow
data:
enrichment_campaigns.json: |
{
"schema": "iglu:com.snowplowanalytics.snowplow/campaign_attribution/jsonschema/1-0-1",
"data": {
"name": "campaign_attribution",
"vendor": "com.snowplowanalytics.snowplow",
"enabled": true,
"parameters": {
"mapping": "static",
"fields": {
"mktMedium": ["utm_medium", "medium"],
"mktSource": ["utm_source", "source"],
"mktTerm": ["utm_term", "legacy_term"],
"mktContent": ["utm_content"],
"mktCampaign": ["utm_campaign", "cid", "legacy_campaign"]
}
}
}
}
enrichment_pii.json: |
{
"schema": "iglu:com.snowplowanalytics.snowplow.enrichments/pii_enrichment_config/jsonschema/2-0-0",
"data": {
"vendor": "com.snowplowanalytics.snowplow.enrichments",
"name": "pii_enrichment_config",
"emitEvent": true,
"enabled": true,
"parameters": {
"pii": [
{
"pojo": {
"field": "user_ipaddress"
}
}
],
"strategy": {
"pseudonymize": {
"hashFunction": "MD5",
"salt": "<SALT>"
}
}
}
}
}
enrichment_event_fingerprint.json: |
{
"schema": "iglu:com.snowplowanalytics.snowplow/event_fingerprint_config/jsonschema/1-0-1",
"data": {
"name": "event_fingerprint_config",
"vendor": "com.snowplowanalytics.snowplow",
"enabled": true,
"parameters": {
"excludeParameters": ["cv", "eid", "nuid", "stm"],
"hashAlgorithm": "MD5"
}
}
}
enrichment_referrer_parser.json: |
{
"schema": "iglu:com.snowplowanalytics.snowplow/referer_parser/jsonschema/2-0-0",
"data": {
"name": "referer_parser",
"vendor": "com.snowplowanalytics.snowplow",
"enabled": true,
"parameters": {
"database": "referers-latest.json",
"uri": "https://snowplow-hosted-assets.s3.eu-west-1.amazonaws.com/third-party/referer-parser/",
"internalDomains": []
}
}
}
enrichment_ua_parser.json: |
{
"schema": "iglu:com.snowplowanalytics.snowplow/ua_parser_config/jsonschema/1-0-1",
"data": {
"name": "ua_parser_config",
"vendor": "com.snowplowanalytics.snowplow",
"enabled": true,
"parameters": {
"uri": "https://snowplow-hosted-assets.s3.eu-west-1.amazonaws.com/third-party/ua-parser",
"database": "regexes-latest.yaml"
}
}
}
enrichment_yauaa.json: |
{
"schema": "iglu:com.snowplowanalytics.snowplow.enrichments/yauaa_enrichment_config/jsonschema/1-0-0",
"data": {
"enabled": true,
"vendor": "com.snowplowanalytics.snowplow.enrichments",
"name": "yauaa_enrichment_config"
}
}
config.hocon: |
{
"auth": {
"type": "Gcp"
},
"input": {
"type": "PubSub",
"subscription": "projects/<GCP-PROJECT>/subscriptions/snowplow-raw"
},
"output": {
"good": {
"type": "PubSub",
"topic": "projects/<GCP-PROJECT>/topics/snowplow-enriched",
"attributes": [ "app_id", "event_name" ]
},
"bad": {
"type": "PubSub",
"topic": "projects/<GCP-PROJECT>/topics/snowplow-bad-1"
}
},
"assetsUpdatePeriod": "10080 minutes"
}
iglu-config.json: |
{
"schema": "iglu:com.snowplowanalytics.iglu/resolver-config/jsonschema/1-0-3",
"data": {
"cacheSize": 500,
"cacheTtl": 600,
"repositories": [
{
"connection": {
"http": {
"uri": "http://iglucentral.com"
}
},
"name": "Iglu Central",
"priority": 10,
"vendorPrefixes": []
},
{
"connection": {
"http": {
"uri": "http://mirror01.iglucentral.com"
}
},
"name": "Iglu Central - Mirror 01",
"priority": 20,
"vendorPrefixes": []
},
{
"connection": {
"http": {
"apikey": "<Iglu superApiKey>",
"uri": "http://iglu-server-service/api"
}
},
"name": "Iglu Server",
"priority": 0,
"vendorPrefixes": []
}
]
}
}
And here is the Enrich deployment file:
# snowplow/enrich.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: enrich-server
namespace: snowplow
spec:
selector:
matchLabels:
app: enrich
replicas: 1
revisionHistoryLimit: 1
template:
metadata:
labels:
app: enrich
spec:
serviceAccountName: snowplow-service-account
containers:
- name: enrich-server
image: snowplow/snowplow-enrich-pubsub:3.9.0
command:
- "/home/snowplow/bin/snowplow-enrich-pubsub"
- "--config"
- "/snowplow/config/config.hocon"
- "--iglu-config"
- "/snowplow/config/iglu-config.json"
- "--enrichments"
- "/snowplow/config/enrichments"
imagePullPolicy: "IfNotPresent"
env:
- name: JAVA_OPTS
value: -Dorg.slf4j.simpleLogger.defaultLogLevel=info -Dorg.slf4j.simpleLogger.log.InvalidEnriched=debug
volumeMounts:
- name: enrich-config-volume
mountPath: /snowplow/config
resources:
requests:
memory: "256Mi"
cpu: "350m"
limits:
memory: "1.5Gi"
cpu: 2
volumes:
- name: enrich-config-volume
configMap:
name: enrich-configmap
items:
- key: iglu-config.json
path: iglu-config.json
- key: config.hocon
path: config.hocon
- key: enrichment_campaigns.json
path: enrichments/enrichment_campaigns.json
- key: enrichment_pii.json
path: enrichments/enrichment_pii.json
- key: enrichment_event_fingerprint.json
path: enrichments/enrichment_event_fingerprint.json
- key: enrichment_referrer_parser.json
path: enrichments/enrichment_referrer_parser.json
- key: enrichment_ua_parser.json
path: enrichments/enrichment_ua_parser.json
Data Warehouse Loaders
We have three (or four if you count the mutator-init server) more deployments to deploy:
- streamloader
- repeater
- mutator
- mutator-init (A one time user table initialization service)
These services are exteremely similar, and share the same configuration file. For the most up-to-date configuration documents, checkout BigQuery Loader page
Let us start with the configuration file. In the configuration file below, you just need to replace:
<GCP-PROJECT><Iglu superApiKey>
with their appropriate values.
# snowplow/streamloader-config.yaml
kind: ConfigMap
apiVersion: v1
metadata:
name: streamloader-configmap
namespace: snowplow
data:
config.hocon: |
{
"projectId": "<GCP-PROJECT>",
"loader": {
"input": {
"subscription": "snowplow-enriched"
},
"output": {
"good": {
"datasetId": "snowplow",
"tableId": "events"
},
"bad": {
"topic": "snowplow-bq-bad-rows"
},
"types": {
"topic": "snowplow-bq-loader-server-types"
},
"failedInserts": {
"topic": "snowplow-bq-loader-server-failed-inserts"
}
}
},
"mutator": {
"input": {
"subscription": "snowplow-bq-loader-server-types"
},
"output": {
"good": ${loader.output.good}
}
},
"repeater": {
"input": {
"subscription": "snowplow-bq-loader-server-failed-inserts"
},
"output": {
"good": ${loader.output.good}
"deadLetters": {
"bucket": "gs://spangle-snowplow-bq-loader-dead-letter"
}
}
}
}
iglu-config.json: |
{
"schema": "iglu:com.snowplowanalytics.iglu/resolver-config/jsonschema/1-0-3",
"data": {
"cacheSize": 500,
"cacheTtl": 600,
"repositories": [
{
"connection": {
"http": {
"uri": "http://iglucentral.com"
}
},
"name": "Iglu Central",
"priority": 10,
"vendorPrefixes": []
},
{
"connection": {
"http": {
"uri": "http://mirror01.iglucentral.com"
}
},
"name": "Iglu Central - Mirror 01",
"priority": 20,
"vendorPrefixes": []
},
{
"connection": {
"http": {
"apikey": "<Iglu superApiKey>",
"uri": "http://iglu-server-service/api"
}
},
"name": "Iglu Server",
"priority": 0,
"vendorPrefixes": []
}
]
}
}
Streamloader
Now we can easily deploy the streamloader:
# snowplow/streamloader.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: streamloader-server
namespace: snowplow
spec:
selector:
matchLabels:
app: streamloader
replicas: 1
revisionHistoryLimit: 1
template:
metadata:
labels:
app: streamloader
spec:
serviceAccountName: snowplow-service-account
containers:
- name: streamloader-server
image: snowplow/snowplow-bigquery-streamloader:1.7.1
command:
- "/home/snowplow/bin/snowplow-bigquery-streamloader"
- "--config"
- "/snowplow/config/config.hocon"
- "--resolver"
- "/snowplow/config/iglu-config.json"
imagePullPolicy: "IfNotPresent"
env:
- name: JAVA_OPTS
value: -Dorg.slf4j.simpleLogger.defaultLogLevel=info
volumeMounts:
- name: streamloader-config-volume
mountPath: /snowplow/config
resources:
requests:
memory: "256Mi"
cpu: "250m"
limits:
memory: "2Gi"
volumes:
- name: streamloader-config-volume
configMap:
name: streamloader-configmap
items:
- key: iglu-config.json
path: iglu-config.json
- key: config.hocon
path: config.hocon
Repeater
Deploying repeater is done quite easily as well:
# snowplow/repeater.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: repeater-server
namespace: snowplow
spec:
selector:
matchLabels:
app: repeater
replicas: 1
revisionHistoryLimit: 1
template:
metadata:
labels:
app: repeater
spec:
serviceAccountName: snowplow-service-account
containers:
- name: repeater-server
image: snowplow/snowplow-bigquery-repeater:1.7.1
command:
- "/home/snowplow/bin/snowplow-bigquery-repeater"
- "--config"
- "/snowplow/config/config.hocon"
- "--resolver"
- "/snowplow/config/iglu-config.json"
- "--bufferSize=20"
- "--timeout=20"
- "--backoffPeriod=900"
imagePullPolicy: "IfNotPresent"
env:
- name: JAVA_OPTS
value: -Dorg.slf4j.simpleLogger.defaultLogLevel=info
volumeMounts:
- name: repeater-config-volume
mountPath: /snowplow/config
resources:
requests:
memory: "128Mi"
cpu: "150m"
limits:
memory: "512Mi"
volumes:
- name: repeater-config-volume
configMap:
name: streamloader-configmap
items:
- key: iglu-config.json
path: iglu-config.json
- key: config.hocon
path: config.hocon
Mutator
Deploying mutator is also easy:
# snowplow/mutator.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: mutator-server
namespace: snowplow
spec:
selector:
matchLabels:
app: mutator
replicas: 1
revisionHistoryLimit: 1
template:
metadata:
labels:
app: mutator
spec:
serviceAccountName: snowplow-service-account
containers:
- name: mutator-server
image: snowplow/snowplow-bigquery-mutator:1.7.1
command:
- "/home/snowplow/bin/snowplow-bigquery-mutator"
- "listen"
- "--config"
- "/snowplow/config/config.hocon"
- "--resolver"
- "/snowplow/config/iglu-config.json"
imagePullPolicy: "IfNotPresent"
env:
- name: JAVA_OPTS
value: -Dorg.slf4j.simpleLogger.defaultLogLevel=info
volumeMounts:
- name: mutator-config-volume
mountPath: /snowplow/config
resources:
requests:
memory: "128Mi"
cpu: "150m"
limits:
memory: "512Mi"
volumes:
- name: mutator-config-volume
configMap:
name: streamloader-configmap
items:
- key: iglu-config.json
path: iglu-config.json
- key: config.hocon
path: config.hocon
Mutator Init
Mutator comes with another serivce, mutator-init, which has a one time utility to create the BigQuery table. A similar description file deploys mutator-init service:
# snowplow/mutator-init.yaml
apiVersion: v1
kind: Pod
metadata:
name: mutator-init-server
namespace: snowplow
spec:
serviceAccountName: snowplow-service-account
containers:
- name: mutator-init-server
image: snowplow/snowplow-bigquery-mutator:1.7.1
command:
- "/home/snowplow/bin/snowplow-bigquery-mutator"
- "create"
- "--config"
- "/snowplow/config/config.hocon"
- "--resolver"
- "/snowplow/config/iglu-config.json"
- "--partitionColumn=collector_tstamp"
- "--requirePartitionFilter"
imagePullPolicy: "IfNotPresent"
env:
- name: JAVA_OPTS
value: -Dorg.slf4j.simpleLogger.defaultLogLevel=info
volumeMounts:
- name: mutator-config-volume
mountPath: /snowplow/config
resources:
requests:
memory: "128Mi"
cpu: "150m"
limits:
memory: "512Mi"
volumes:
- name: mutator-config-volume
configMap:
name: streamloader-configmap
items:
- key: iglu-config.json
path: iglu-config.json
- key: config.hocon
path: config.hocon
Endpoint
Finally we need to create the endpoint to receive incoming tracking calls and pass them to the collector service. In the following, you need to:
- Replace
<TRACKER.DOMAIN>with the tracker’s domain name. Something liketracker.example.com. - Replace the name of the managed certificate from
tracker-domain-certificateto something more sensible, something liketracker-example-com.
# snowplow/endpoint.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: snowplow-ingress
namespace: snowplow
annotations:
kubernetes.io/ingress.global-static-ip-name: snowplow-ingress-ip
networking.gke.io/managed-certificates: tracker-domain-certificate
networking.gke.io/v1beta1.FrontendConfig: http-to-https
# kubernetes.io/ingress.allow-http: "true"
spec:
rules:
- host: <TRACKER.DOMAIN>
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: collector-server-service
port:
number: 8080
---
apiVersion: networking.gke.io/v1beta1
kind: FrontendConfig
metadata:
name: http-to-https
namespace: snowplow
spec:
redirectToHttps:
enabled: true
responseCodeName: MOVED_PERMANENTLY_DEFAULT
---
apiVersion: networking.gke.io/v1
kind: ManagedCertificate
metadata:
name: tracker-domain-certificate
namespace: snowplow
spec:
domains:
- <TRACKER.DOMAIN>
Wrap Up
Now you should have 14 files in snowplow folder for kubernetes:
snowplow
├── README.md
├── collector-config.yaml
├── collector.yaml
├── endpoint.yaml
├── enrich-config.yaml
├── enrich.yaml
├── iglu-config.yaml
├── iglu.yaml
├── mutator-init.yaml
├── mutator.yaml
├── namespace.yaml
├── repeater.yaml
├── service-account.yaml
├── streamloader-config.yaml
└── streamloader.yaml