Deploying Snowplow 1 - Architecture
28 Sep 2024In this article, we explain our deployment of Snowplow Open Source on the GCP platform. Our deployment collects events, passes them to PubSub on GCP, and then stores them in BigQuery. This deployment is made possible primarily due to a great (though slightly outdated) document, Highly Available Snowplow Pipeline on Kubernetes and GCP. However, there are a few key differences in our deployment compared to that document:
-
We use Terraform to provision our cloud infrastructure, which makes the deployment cleaner, more manageable, and easier to inspect and replicate.
-
We use Google Cloud’s Workload Identity Federation to authenticate workloads, greatly simplifying the configuration files, as we will demonstrate below.
-
We also simplify our deployment by using only one service account for different service types. We have consolidated all the required permissions and assigned them to one service account for simplicity. Of course, you can define multiple service accounts. For example, our reference document uses three separate service accounts for better security.
Before we continue, we should also mention that, as of January 8, 2024, Snowplow has changed its license agreement from Apache 2 to its own agreement called Introducing the Snowplow Limited Use License Agreement, which limits how you can use Snowplow’s open source. In particular, it states:
You cannot run this software in production in a highly available manner. For current users of Snowplow Open Source Software who want high availability capabilities in production, you must contact Snowplow for a commercial license. However, SLULA does allow you to run highly available development and QA pipelines that are not for production use
Therefore, in order to use Snowplow in production, we need to use images that were released before January 8, 2024. That is why we are not using the latest versions of the Docker images, as you will see later in this post.
We divide this document to three parts:
In the first part, we will briefly go over the architecture and explain the types of services needed for Snowplow to function properly. In the second part, we will explain how to deploy the required infrastructure, such as PubSub topics, subscriptions, and the PostgreSQL databases used by the Iglu server. Finally, in the last part, we will explain how to deploy the services in Kubernetes.
Architecture Overview
Perhaps it’s easiest to start with the reference architecture for Snowplow deployment on GCP. Below is the original diagram from Snowplow:
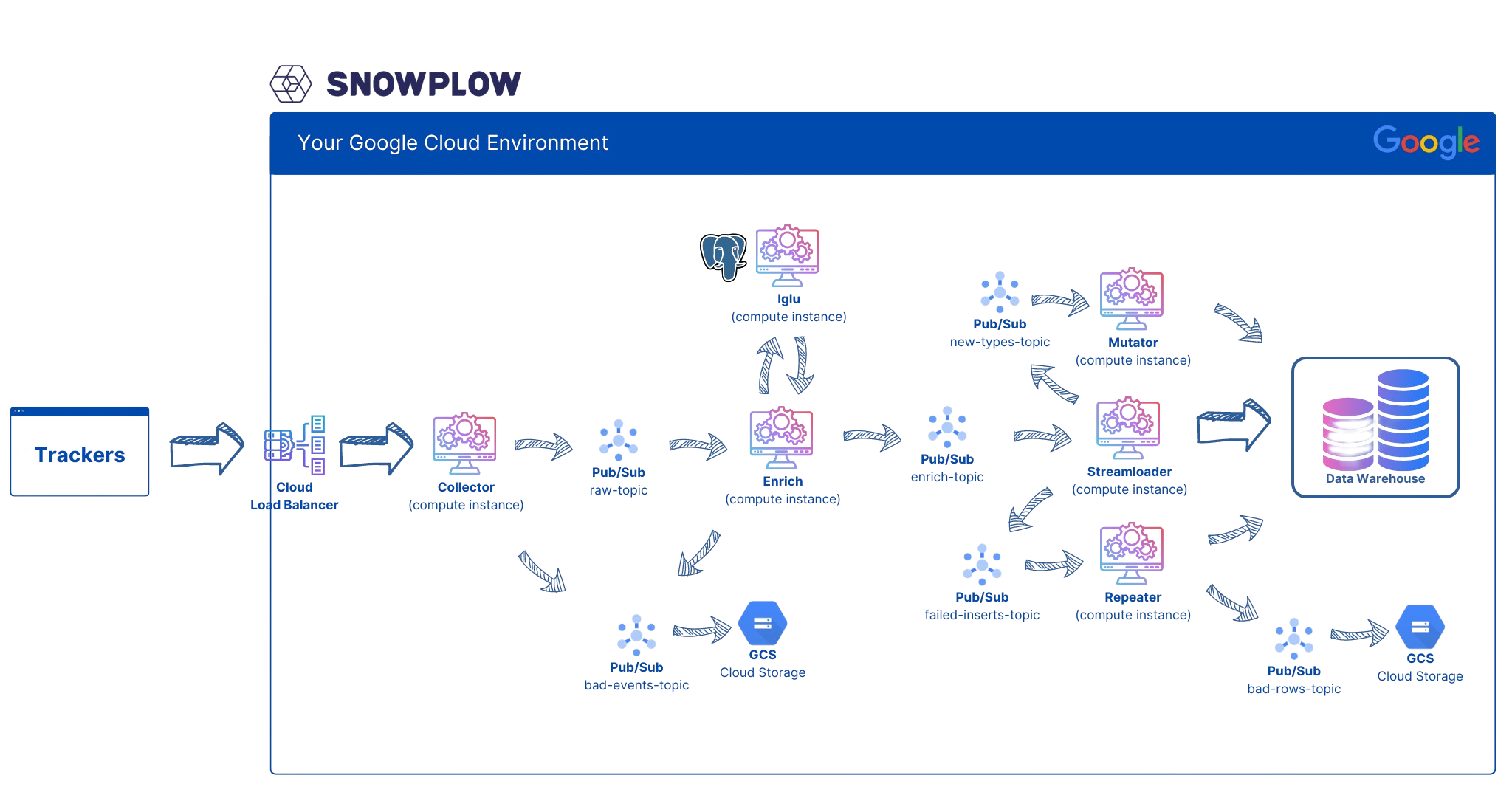
As it can be seen in the diagram, we need to deploy six types of services on our Kubernetes cluster:
- Iglu
- Collector
- Enrich
- Streamloader
- Repeater
- Mutator
We also need to create six PubSub topics:
-
raw-topic — called snowplow-raw in our implementation
The Enrich service subscribes to this topic through a subscription with the same name, snowplow-raw. It reads the events, enriches them, and adds them to the enrich-topic. -
bad-events-topic — called snowplow-bad-1
We connect this topic directly to GCS via a subscription called snowplow-bad-1-gcs. -
enrich-topic — called snowplow-enriched
The Streamloader service subscribes to this topic through a subscription with the same name, snowplow-enriched, and writes the events to BigQuery. -
new-types-topic — called snowplow-bq-loader-server-types
In case new columns need to be created in the BigQuery events table, Streamloader adds a message to this topic. The Mutator service subscribes to this topic through a subscription with the same name, snowplow-bq-loader-server-types, and creates the required columns. -
failed-inserts-topic — called snowplow-bq-loader-server-failed-inserts
If Streamloader cannot write to BigQuery, it adds events to this topic. The Repeater service subscribes to this topic through a subscription with the same name, snowplow-bq-loader-server-failed-inserts, to retry inserting them into BigQuery. -
bad-rows-topic — called snowplow-bq-bad-rows
After multiple unsuccessful retries by the Repeater service to write failed events to BigQuery, it writes them to this topic. We connect this topic directly to GCS via a subscription called snowplow-bq-bad-rows-gcs.
In addition, we need:
- Kubernetes ingress (Load Balancer)
- PostgreSQL for Iglu Server
-
Three GCS buckets: To write bad rows, failed inserts, etc as mentioned above. We have prefixed them with spangle to make the names unique in the GCS space. Feel free to use your preferred names of course:
- spangle-snowplow-bad-1
- spangle-snowplow-bq-bad-rows
- spangle-snowplow-bq-loader-dead-letter
- Service account to allow Snowplow services interaction with GCP resources
- Fixed IP address for tracker
- BigQuery dataset to hold the events table
In part 2 and part 3 we will overview how to create each of the resources mentioned above.